mdciao: Accessible Analysis and Visualization of Molecular Dynamics Simulation Data
![]()
![]()
![]()
![]()
![]()


mdciao is a Python module that provides quick, “one-shot” command-line tools to analyze molecular simulation data using residue-residue distances. mdciao tries to automate as much as possible for non-experienced users while remaining highly customizable for advanced users, by exposing an API to construct your own analysis workflow.
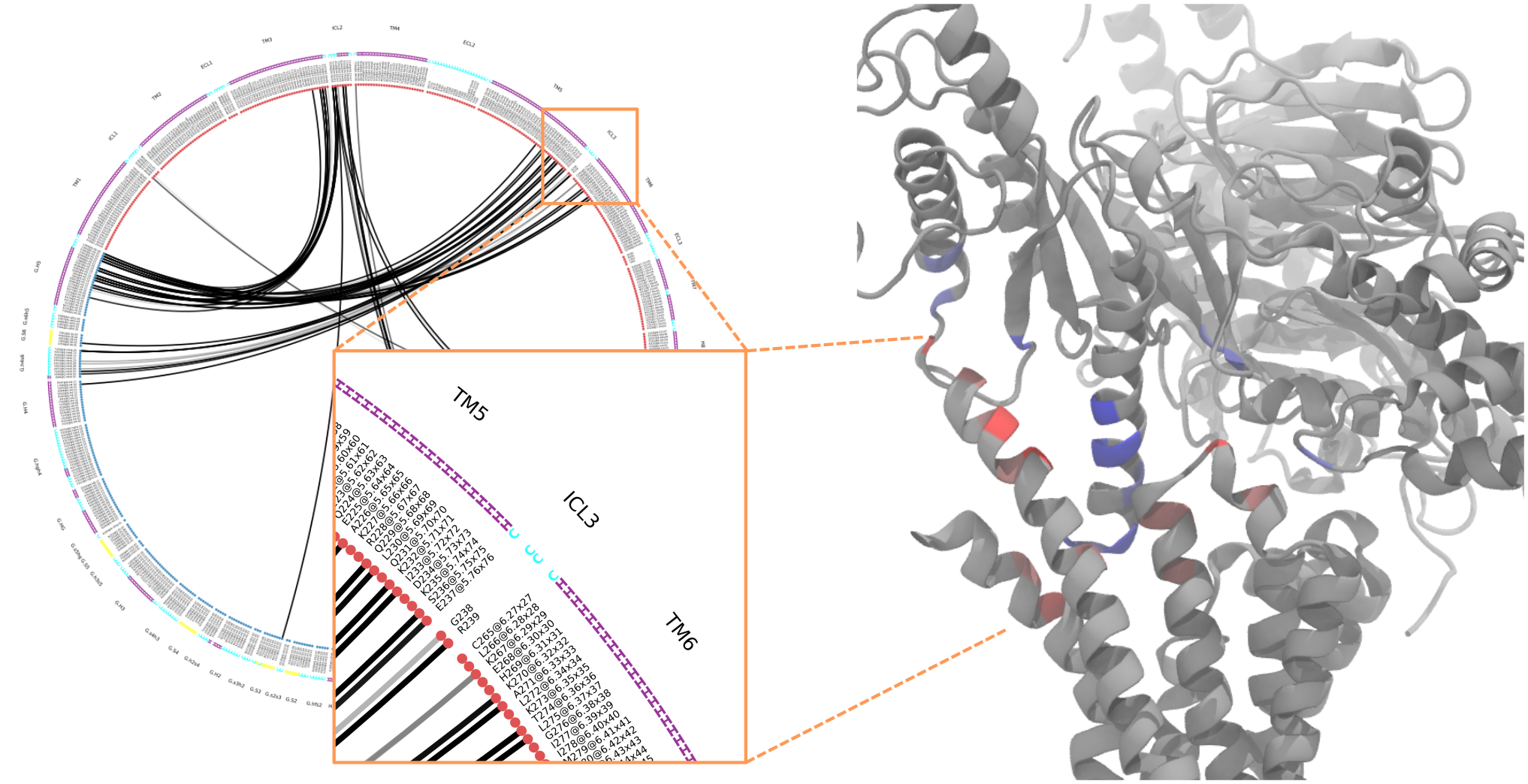
Under the hood, the module mdtraj is doing most of the computation and handling of molecular information, using BioPython for sequence alignment, pandas for many table and IO related operations, and matplotlib for visualization. It tries to automatically use the consensus nomenclature for
- GPCRs
via Ballesteros-Weinstein-Numbering or structure-based schemes by Gloriam et al for the receptor’s TM domain, or
via generic-residue-numbering for the GAIN domain of adhesion GPCRs
- G-proteins
- Kinases
via their 85 pocket-residue numbering scheme
using local files or on-the-fly lookups of the GPCRdb and/or KLIFS.
Basic Principle
mdciao takes the files typically generated by a molecular dynamics (MD) simulation, i.e.
topology files, like prot.gro or top.pdb
trajectory files, like traj1.xtc, traj2.xtc
and calculates the time-traces of residue-residue distances, and from there, contact frequencies and distance distributions. The most simple command line call would look approximately like this:
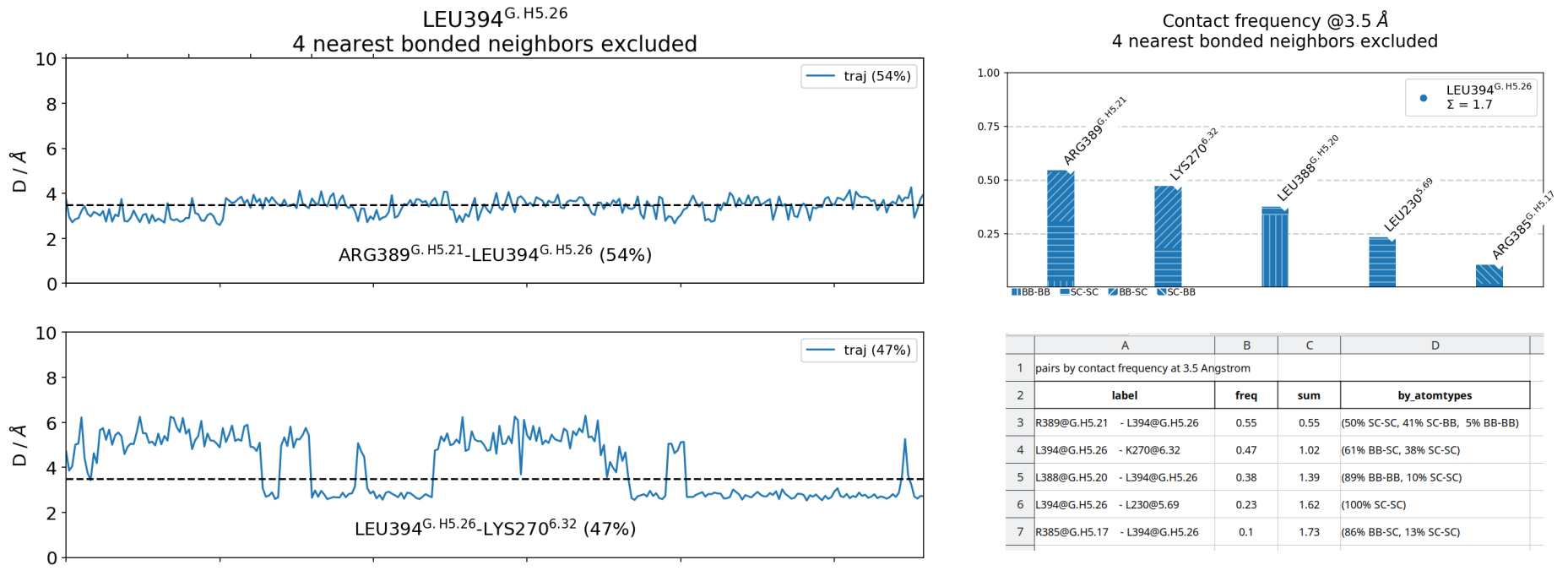
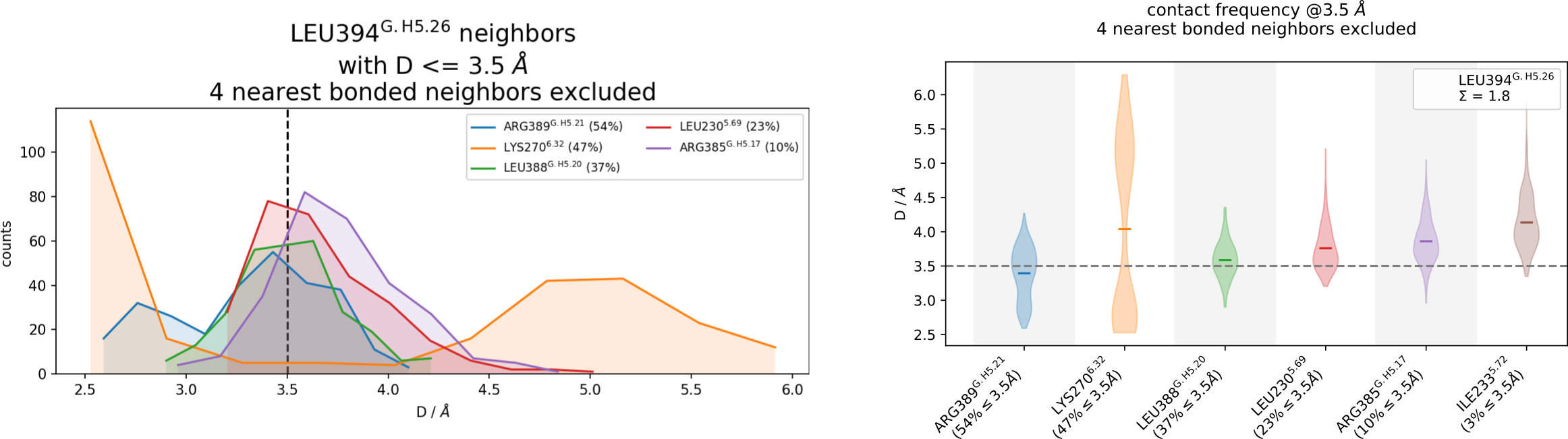
mdc_neighborhoods.py top.pdb traj.xtc --residues L394
[...]
The following 6 contacts capture 5.26 (~97%) of the total frequency 5.43 (over 9 contacts with nonzero frequency at 4.50 Angstrom).
As orientation value, the first 6 ctcs already capture 90.0% of 5.43.
The 6-th contact has a frequency of 0.52.
freq label residues fragments sum
1 1.00 L394@frag0 - L388@frag0 353 - 347 0 - 0 1.00
2 1.00 L394@frag0 - R389@frag0 353 - 348 0 - 0 2.00
3 0.97 L394@frag0 - L230@frag3 353 - 957 0 - 3 2.97
4 0.97 L394@frag0 - R385@frag0 353 - 344 0 - 0 3.94
5 0.80 L394@frag0 - I233@frag3 353 - 960 0 - 3 4.74
6 0.52 L394@frag0 - K270@frag3 353 - 972 0 - 3 5.26
The following files have been created:
./neighborhood.overall@4.5_Ang.pdf
./neighborhood.LEU394@frag0@4.5_Ang.dat
./neighborhood.LEU394@frag0.time_trace@4.5_Ang.pdf
You can also invoke:
mdc_examples.py
for a list of all the built-in command-line toy-examples or:
mdc_notebooks.py
for live Jupyter notebooks play around with. These are shown in the Jupyter Notebook Gallery along with other real-life, more elaborated examples.
Note
A note of caution regarding the above definitions for contact and frequency:
the kinetic information is averaged out. Contacts quickly breaking and forming and contacts that break (or form) only once will have the same frequency as long as the fraction of total time they are formed is the same. For analysis taking kinetics into account, use. e.g. pyemma.
The sharp, “distance-only” cutoff can sometimes over- or under-represent some interaction types. Modules like get_contacts or ProLIF and the PLIP webserver have individual geometric definitions for each interaction type.
Frequencies are just averages over the input data. In some cases, simply computing averages is a bad idea. The user is responsible for deciding over what data to average. For example, if your data is highly heterogenous you might want to cluster your data into into
cluster1.xtc,cluster.2.xtcetc and then do a per-cluster analysis withmdciao. Same applies to single frames i.e. PDB files, where the word “frequency” doesn’t make any sense.
These issues (if/when they arise) can be spotted easily by looking at the time-traces and informed decisions can be made wrt to parameters like the cutt-off value, number of contacts displayed and many others.